The success of an online service with millions of users worldwide, and an interactive audience of several thousand, depends on a well architected and engineered software platform. Our engineering team has recently updated the software stack we use to build and deploy back-end (JVM-based) services for such an online service. In this post I share the choices we made, as well as some of the background (motivation behind the project, benefits we were looking to gain). This might help if you’re undertaking a similar strategic review and update of the software stack and deployment approach for your back-end services in the near future.
1) Background
From its early days (over 5 years ago) our platform has been distributed, and based on what could be described as a lightweight service-oriented architecture. We have multiple back-end services, each responsible for supporting a chunk of the platform’s functionality. They provide a centralised implementation of business rules and manage access to a repository that masters the subset of the domain entities owned by the service. The services expose their functionality and provide access to (distribute) their data via RESTful web services (XML or JSON over HTTP). The architecture is lightweight from the perspective that we don’t currently use many of the features commonly described for SOA, e.g. service discovery. The implementation of the architecture has not been without its troubles (e.g. sizing of the services, and the APIs never seeming to be perfect or complete) but fundamentally it has served us well as the platform has grown and matured.
The (largely open-source) software we’ve used to build our platform has always evolved to meet the changing needs and priorities of the business as it has grown and matured. But, for one reason and another, the stack we were using to build, deploy and run our existing services had not been updated for several years. In the intervening period some major advances had been made in programming languages, application frameworks, APIs, and tools, which we weren’t taking advantage of.
2) Current Stack, Packaging and Deployment
Application Software Stack
Our existing back-end services run on the JVM and are all built using Java, on top of a consistent application software stack, a logical view of which is shown below –
 Services depend primarily on Spring (3.x) to provide the application framework – plumbing and cross cutting concerns such as dependency injection (DI) and transaction management, and a consistent programming model (design patterns and APIs). Spring MVC provides the framework for all our RESTful web services, with it’s excellent counterpart RestTemplate also simplifying the consumption of REST APIs.
Services depend primarily on Spring (3.x) to provide the application framework – plumbing and cross cutting concerns such as dependency injection (DI) and transaction management, and a consistent programming model (design patterns and APIs). Spring MVC provides the framework for all our RESTful web services, with it’s excellent counterpart RestTemplate also simplifying the consumption of REST APIs.
We only use a small number of the most common JEE APIs. Most are used indirectly, with Spring providing simplified, consistent abstracted APIs. The key ones being Servlet, underpinning the use of Spring MVC; and JMS for asynchronous processing of requests. We also use JTA for the odd global transaction (across DB and queue).
A few third-party libraries (e.g. Apache Commons *) are used to address the common shortfalls in Java (6 / 7) and to bolt-on implementations of newer JEE APIs (e.g. Bean Validation) not supported by the current version of our app server.
Build, Packaging and Deployment
Services are built using ANT (and Ivy), packaged as WAR files, and deployed to one of several instances of a centralised JEE (5) app server each running in its own JVM, as shown below.
 Whilst we’ve made efforts to keep the version of Java up to date, other aspects of the stack have become dated. We’re still using JEE 5 because it’s coupled to the version of the centralised JEE app server to which all our services are deployed. This app server is now end-of-life with no obvious upgrade path.
Whilst we’ve made efforts to keep the version of Java up to date, other aspects of the stack have become dated. We’re still using JEE 5 because it’s coupled to the version of the centralised JEE app server to which all our services are deployed. This app server is now end-of-life with no obvious upgrade path.
3) Aims and Opportunities
The major aims of the project were as follows –
1) Replace end-of-life app server – We had to get-off our current app server and on to one that’s maintained, supported and actively developed. This was necessary not only to gain access to newer container APIs and services, but also to address security exploits.
2) Decouple service deployment and run-time (remove cross-service dependencies) – The current practice of deploying multiple services to the same, centralised app server has a number of downsides –
a) Harder to upgrade Java & JEE – In addition to the app server itself, all our services currently share the same versions of Java and JEE, meaning they all need to be upgraded at the same time. This increases risk and creates inertia.
b) More expensive to scale – A centralised app server capable of running multiple services requires a larger, more powerful server, than a server supporting a single service. This is more expensive to scale horizontally (requiring larger increments of hardware).
c) Need for generic configuration and tuning – The JVM and app server instance has to be generically configured to support all the services deployed in the given instance, rather than being tuned to suit one particular service’s workload.
For these reasons (simplify Java upgrades; more cost-effective scaling; allow service specific JVM tuning) a major goal of the project was to isolate (decouple) services at deployment and runtime.
3) Boost developer productivity – We wanted to take advantage of the productivity improvements that newer Java frameworks, libraries and dev tools could offer with a view to delivering requirements more quickly. These include writing less code e.g. by using new frameworks which offer convention-over-configuration and which remove the need for boilerplate (e.g. persistence logic). Also, speeding-up everyday dev cycles by e.g. reducing the need for time consuming re-deployments through more efficient testing, and hot code reloading; and quicker app server startup times.
4) Gain access to new Java APIs – New and improved standard APIs have become available, including support for building more scalable and responsive (reactive) applications. JEE (7) for example now provides support for async processing of web requests, a new standard API is available for using websockets, and an enhanced (JMS) API is available for simpler messaging.
4) Requirements and Constraints
The following requirements and constraints were used to guide the selected shortlist of candidate solutions (new, replacement stacks).
JVM-based
The JVM continues to be the most robust, scalable and portable runtime platform available, with great performance, and good monitoring and management support. As of today it supports many languages beyond Java. It’s also well supported by many PaaS platforms (AWS Elastic Beanstalk, Heroku, Cloud Foundry, etc). The replacement stack therefore had to continue to run on the JVM.
Leaner, but extensible
At its core the new stack should just support the essentials – building services that run on the JVM, that are configurable, capable of managing their own data, and exposing it securely via RESTful web APIs. Support for additional features (e.g. messaging) should be optional, but easy to layer-on when needed, rather than the current one-size-fits-all approach. This reduces the complexity for dev and ops to deal with, lowers total hardware (CPU and memory) costs across all environments, and leads to more cost effective scaling.
Conversely, the stack shouldn’t be too lean as to overlook the need for production features, such as logging, monitoring and management.
Convention-over-configuration
As a means of fulfilling one of the stated project goals of boosting developer productivity, the components of the new stack should make good use of convention-over-configuration where possible. This requirement would strongly influence the choice of application framework.
PaaS compatibility
Making effective use of the Cloud, where appropriate, is strategically important. Our business has peaks (spikes) and troughs in demand at certain times of the day and week. meaning we can take advantage of the cost-savings of on-demand scaling. We also want to take advantage of the simpler deployment and operations (management) which a PaaS can offer. The new application software stack must therefore be supported and run equally well on our chosen PaaS platform (AWS Elastic Beanstalk), as well as on-premise.
5) New Stack, Packaging and Deployment
Application Software Stack
After prototyping an end-to-end slice of one our services, and discussing it among the team, we decided to adopt the following new stack –
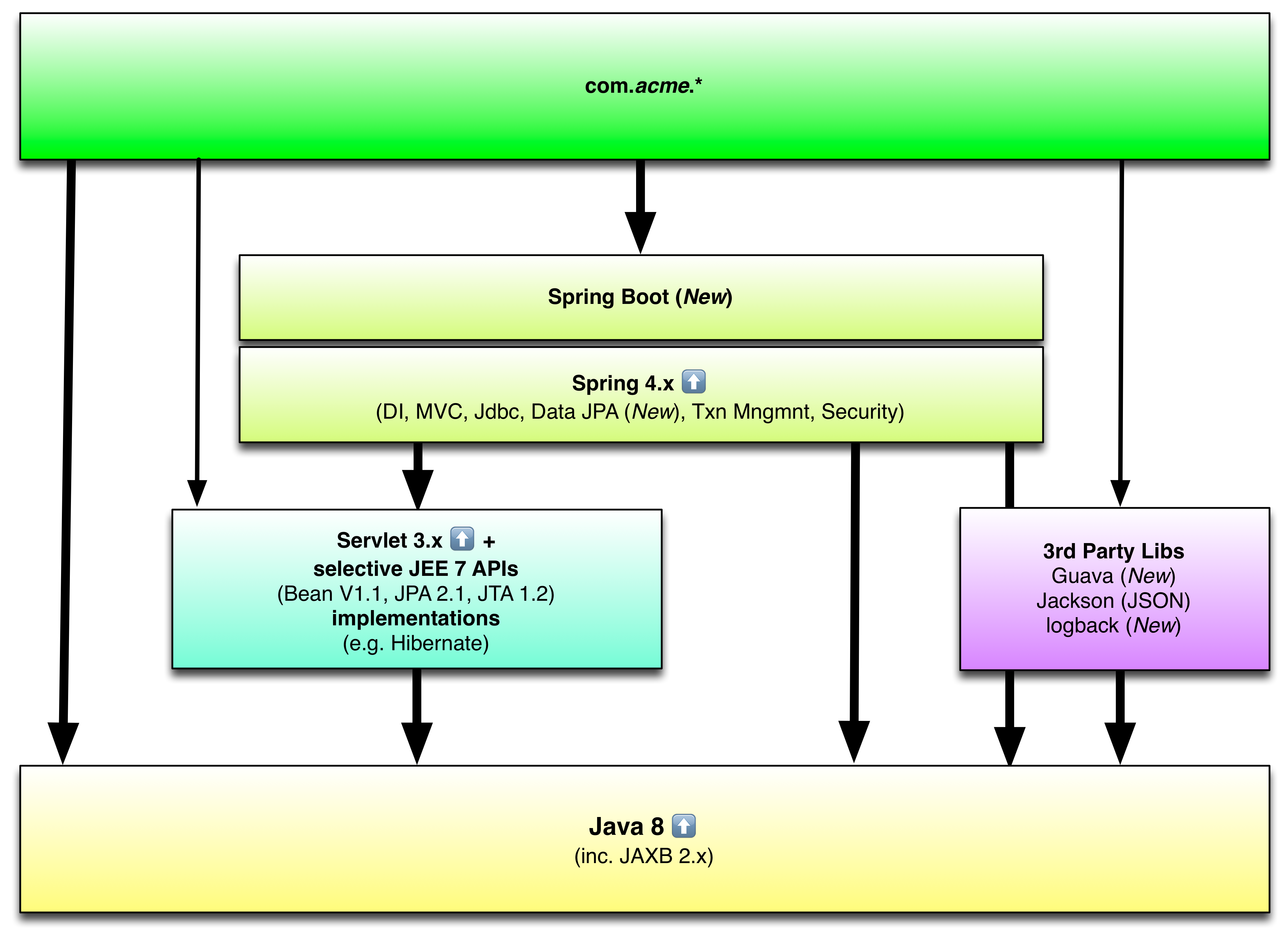 As can be seen, this is an evolutionary rather than revolutionary choice. There are some good reasons for this.
As can be seen, this is an evolutionary rather than revolutionary choice. There are some good reasons for this.
Programming Language
Given our team’s skills and experience, only a couple of JVM languages (Groovy and Scala) other than Java were considered. I’d had a positive first impression of using Scala, and could see how our team could start by using it as a better (more concise and powerful) Java. We also already use Groovy to a small extent to write our tests. However, we decided to stick with Java. We wouldn’t have done this if it weren’t for the major new features (Lambdas, Streams API, better Date/Time etc) added to Java 8 and signs that major development of the language was moving forward again. (There’s nothing stopping us adopting Scala or Groovy in the future. Its use would be compatible with the rest of the stack).
Application framework
The following Java/JVM application frameworks were shortlisted:
- Play framework
- Dropwizard
- Spring Boot
Using a lighter-weight, REST API only framework, such as Spray was also an option, but wasn’t evaluated at the time.
During prototyping we were impressed by the new features which Spring Boot (which was still a work-in-progress beta at the time) offered, and how well it satisfied some of our goals and requirements.
Convention-over-config – Boot’s focus on convention-over-config is a productivity boon for developing and maintaining services built on Spring. With its intelligent defaults, based on classpath detection, very little if any Spring bean config is required, but it’s easy to override the defaults if needed using Java config (@Configuration). This will slim down our services, removing hundreds of lines of XML config. The starter POMs also simplify dependency management, making it easier to layer-on support for additional Spring modules, and providing tested combinations of third-party dependencies.
Standalone web-services – Boot supports deploying and running a service standalone from the command line, using a combination of an executable jar and an embedded web server / container, with out-of-the-box support for the latest versions of the popular web containers Tomcat and Jetty. This helps us achieve the stated goal of decoupling deployed services, and makes it simpler to get new services in production.
Boot’s enhanced support for environment specific app config is an example of how it simplifies building services. Config common to all environments, and selective overrides for named environments (corresponding to bean profiles) can all be defined in a single YAML file. And the active environment(s) (profiles) can be selected at runtime, using a variety of techniques suiting different deployment scenarios, including Java system properties, command line args and env vars. This removes the need to maintain multiple properties files and generate env specific versions at build time.
In addition to the new features, choosing Boot also means our business can continue to benefit from the dev team’s core Spring and Spring MVC experience. The team can also leverage this experience to take advantage of a range of other Spring projects. A primary example is Spring Data which we can use to accelerate building repositories using JPA (ORM), and to simplify configuring and accessing Redis, using familiar patterns.
JEE APIs
We’ll continue to use a small subset of JEE APIs to build our services, but these will be kept to the essential minimum in interest of keeping the app container as lean as possible.
We’ll be looking to adopt the latest (JEE7) version of these APIs. For our services, the primary benefit of this JEE upgrade is upgrading the Servlet API from 2.5 to 3.1.
Servlet 3.0/3.1 provides a couple of major features that help build more scalable web services, which Spring MVC leverages –
- Non-blocking I/O – Send / receive data without blocking the container’s HTTP thread. This allows Servlet based web MVC frameworks like Spring MVC to operate on a par with the Play framework.
- Delayed request handling – Long running request are detachable from the container thread. Spring MVC uses this to efficiently handle long-running requests by processing tasks in another thread (@Controller returns Java Callable or equivalent Spring DeferredResult).
The next biggest benefit of the JEE upgrade is updating the JPA API from 1.0 to 2.1, with improvements including the criteria query API and several JPQL enhancements.
Libraries
We’ve adopted Google Guava, as our base utility library, in preference to various Apache Commons (Lang, Collections, I/O) libraries. Guava has a modern, well designed set of APIs, which have influenced the development of the Java language (Predicate, Optional, Future, etc) itself. The library is open-source, widely used, well maintained, with a good release cadence.
Build, Packaging and Deployment
Build
Our prototyping also confirmed Gradle as a great choice for building services:
- The build DSL radically shrinks the size of our existing ANT build scripts by being declarative and far more expressive.
- Whilst Gradle has standard tasks and conventions, it’s also easy to customise build logic when required (e.g. to integrate with an in-house deployment system) using the full power of Groovy.
- It supports the ubiquitous Maven repo format for resolving dependencies, as well as Ivy.
- Good IDE integration including built-in support for auto-generation of metadata (project and classpath files), and third-party plugins exist for executing build tasks.
- There is healthy and growing set of plugins available which help integrate other tools e.g. to build and publish a Docker image. (Stay tuned for a future post on using Gradle to build and publish your service as a Docker image).
- Good ANT integration facilitates gradual migration from ANT to Gradle, and also continued use of ANT tasks in Gradle scripts.
In addition, Gradle has proven support for building apps in other languages (including Scala and Groovy) should we need it in future.
Application Server
The full-blown JEE (5) app server is replaced with a slimmer, up to date, embeddable web container supporting the aforementioned Servlet 3.1 API. The additional JEE APIs (JPA, Bean Validation, JTA, etc) are bolted-on as and when needed by integrating proven third-party implementations of these APIs, such as Hibernate. This helps achieve the aim of a leaner, but extensible runtime.
Subject to further performance testing, we’ll likely standardise on using Tomcat (8) for our services. It meets the essential requirements of being embeddable, running on Java 8 and supporting Servlet 3.1, and it’s one of the most widely used Java web containers, and hence is well tested, supported and maintained.
Packaging
Spring Boot is used to package services as fat, executable JARs, that include their own embedded version of the web server / container – the JAR contains all of the service’s dependencies, can be run from the command line, and launches the web container and bootstraps the Spring container.
This allows services to run standalone, independently from one another, helping to achieve the aim of decoupling service’s deployment and runtime. They’re no longer restricted to sharing the services of a central container, or its global libs.
The switch to packaging and running services in their own standalone JARs means each service is now additionally free to choose and evolve the version of the web container and the version of Java it uses, rather than only the application framework as in the past –
 Java upgrades for example can now be tested and rolled-out on a per service basis.
Java upgrades for example can now be tested and rolled-out on a per service basis.
Deployment
At the same time as upgrading the software stack we also decided to update how we deploy our services, adopting the use Docker. There were several reasons why we chose to use Docker–
- Increased service isolation – Services sharing the same server can choose and configure their own software environment, down to the O/S level, without conflicts. For example, each service’s Docker image includes a chosen version of Java. The same can be achieved using a hypervisor, but Linux containers like Docker are more efficient when running multiple services on the same server.
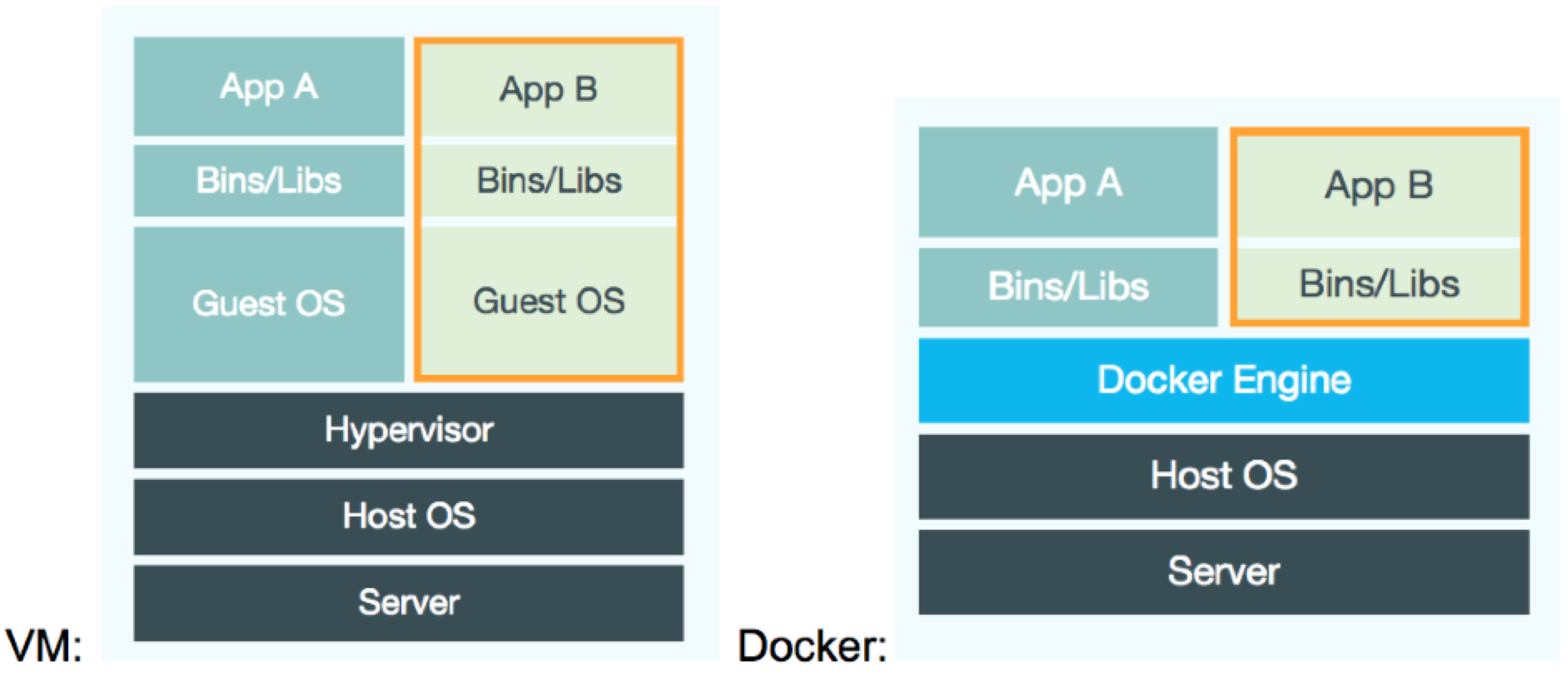
- Reproducible environments – A Docker image contains a release of a service and all of its configured dependencies, down to the O/S. On completion of testing in a QA environment, the resulting image and hence identical runtime environment can be deployed to staging and production environments, with only environment variables needing to change. This reduces the chances of deployments failing due to environments beings setup or configured differently.
- Greater choice / flexibility for PaaS deployment – AWS Elastic Beanstalk (EB) supports Docker as a target platform. Using Docker has the major advantage of allowing us to choose both the implementation and version of Java and web container we want to use. We’re not tied to the versions supported by EB’s Java platform, which often lag behind or may not always be supported.
- Standardisation for on-premise deployment – Standardising on the use of Docker to deploy all our platform components (not just back-end services) means that everything gets deployed in the same way, regardless of the underlying development platform or its runtime. The deployment artefact is a Docker container, and its only requirements are a Docker host. This reduces the need for component specific deployment prerequisites or setup instructions.
6) Wrap-up
Since making the above choices it has been reassuring to discover other companies (e.g. Ticketmaster and Netflix) also choosing to build and deploy their future services in similar ways, as well as the increasing adoption of Spring Boot in general.
Having completed our evaluation and prototyping exercise we’re now in the process of putting our choices to the test. To begin with, we’ve opted to build and deploy a relatively simple new service on the new stack, and get this in production. I plan to share some of the things we’ve learned, including using Spring Boot, Docker and Elastic Beanstalk, in future posts. Watch this space!
Thanks for reading.
