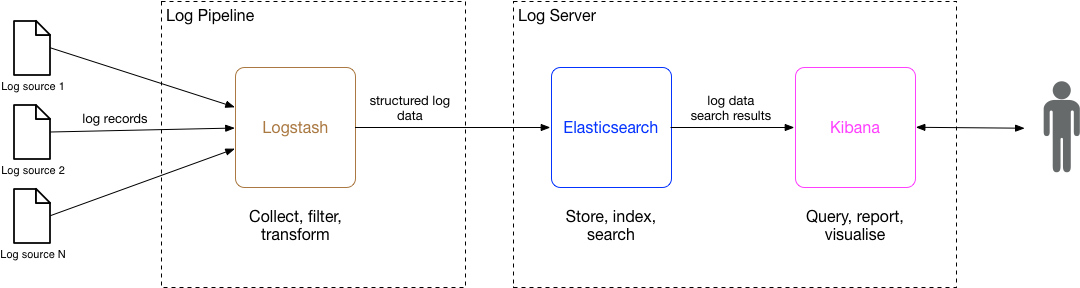
When my team and I first took on responsibility for modernising our business’ backend application services, we found it was hard to obtain a full picture of the events that were being logged by services, in a timely manner. Logging of events are an essential source of data for monitoring how a service is operating, and also to support troubleshooting of problems e.g. the no. and rate of failed API requests, and supporting failure diagnostics. Therefore, one of the first tasks we prioritised as a (devops) team was to improve this situation by provisioning a modern log aggregation and search solution. This post outlines the problems we addressed, the architectural pattern we used as the basis of the solution, the tools we used to implement the pattern, and the resulting benefits.