This is a short post on a couple of approaches to managing the rate of message consumption, their differences and how to choose between them.
Background
At work we’re in the middle of re-architecting a solution to address a performance and scalability problem. An API used to capture and store data generated by our users has been exhibiting slower responses at peak times. Using a combination of application metrics and server monitoring this has been traced to a performance bottleneck in writes to a relational database (RDB). In addition, the API is reliant on a shared RDB server which is struggling to cope with the collective load (writes) at peak times. There’s a risk that the API may not be capable of scaling to support the increase in volume of API calls that will result from projected future growth. The solution we’re pursuing is to split the existing API in two, placing a highly scalable, persistent queue between the API controller (web tier) that accepts the posted data, and the business & persistence logic (app / logic tier) which writes to the RDB. We’ve chosen to use Amazon’s hosted messaging service, Simple Queue Service (SQS) to provide the queue. This queue is capable of much higher write throughput than the current relational database. It also acts as a buffer soaking up spikes in the volume of API calls and taking some of the load off the RBD server. As part of the solution, a new message consumer task also needs to be built to process the queue asynchronously. This is deployed across multiple ‘worker’ nodes for scalability –

Controlling Rate of Message Consumption
A key (technical) requirement is that the total load placed on the shared RDB server at any one time by the message consumers, must be controlled so that it remains below a max no. of database writes per second.
There are two ways to solve this requirement – throttling concurrent message consumer threads and rate limiting. What’s the difference? And what factors might influence which of these approaches you might use?
Throttling Concurrent Consumer Threads
The first approach limits (or ‘throttles’) the rate at which messages are processed by capping the max no. of active message consumer threads at any one time, and controlling the frequency at which they run.
A single thread may consume work faster than you desire, given sufficient hardware resources (primarily CPUs), but this can be managed by controlling the frequency at which it is scheduled, rather than just letting it run in a tight loop (with an optional sleep between polling the queue).
Our application will be responsible for scheduling the message consumer task to run repeatedly at fixed intervals to process the message queue. To provide the best performance, a thread pool will be used to avoid the overhead of creating and destroying a new thread for every execution of the task. In addition to optimising performance, use of a thread pool also provides the opportunity to centrally manage the resources consumed by tasks, including the active no. of message consumer threads.
Java (5+) provides first-class support for implementing managed thread-pools using a java.util.concurrent.ThreadPoolExecutor. This includes the ability to partially control the rate of message consumption by setting the max pool size. (ThreadPoolExecutor uses a queue to hold tasks which, given the core or max pool size settings, cannot be immediately executed. When combining the scheduling of tasks at regular intervals with throttling the execution of the tasks, the implementation of this queue needs to be carefully chosen to avoid unnecessarily queuing large no. of tasks, rather than rejecting them).
Rate Limiting
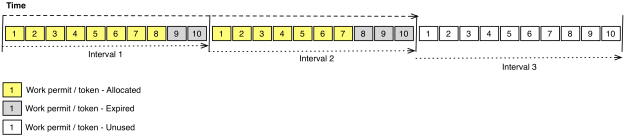
The second approach is rate limiting. This works by limiting the no. units of work that can be performed in a given period. Workers must gain permission to do any work. The actual rate (throughput) at which work is done within a given period is tracked. When it reaches a specified maximum further requests to do more work are rejected, at which point a worker must back-off (block or do something else) until the next period when more rate becomes available. This can be visualised by imagining that there are fixed no. of permits (or tickets) which can be acquired in a given interval. Once these are exhausted, no further work can be done in that period –
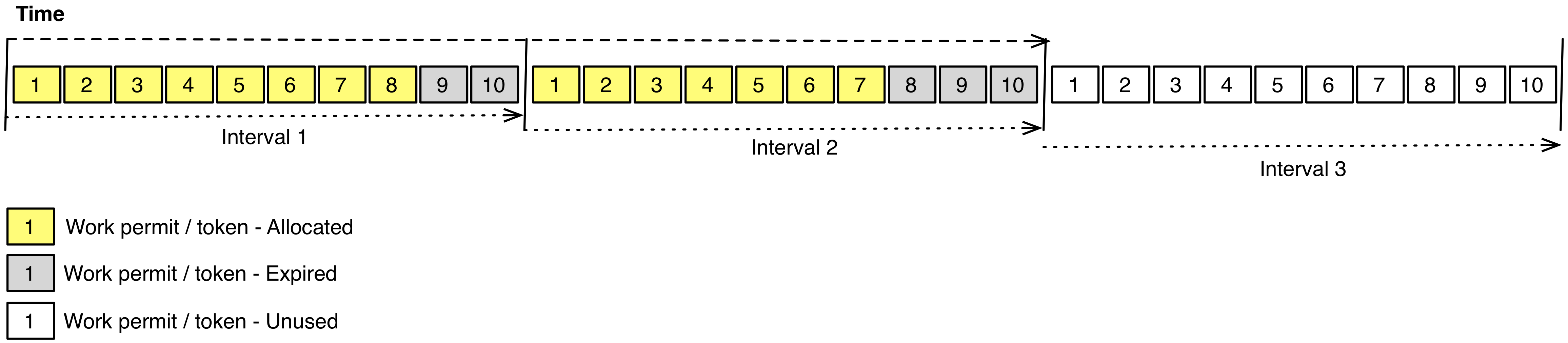
When applying rate limiting to this use-case, the workers are message consumer threads, and the units of work are messages. For rate limiting to provide an acceptable solution to the requirement to cap the load on a DB, the period of time over which the actual rate of message consumption is tracked and limited needs to be fairly small, at least per second.
For this particular use-case, the rate limit would be calculated as follows –
Rate limit = (required max no. of DB writes per sec) / (max no. of DB writes per message), e.g.
- Rate limit = (30 DB writes/sec) / (3 DB writes/msg) = 10 msgs/sec
Central to the design of this solution would be a RateLimiter component, which would be configured with the desired rate limit, provide method(s) which support message consumer threads requesting a permit to do work, and keep track of the actual rate at which work is being done.

The simplest way to implement this solution is a RateLimiter class running in the same JVM as the message consumer, which tracks the actual rate in memory. Google’s Guava library provides such an implementation. See RateLimiter. Although, as explained below, using a co-located rate limiter has its limitations in a load-balanced, horizontally scaled application.
Factors Influencing Choice of Approach
1) Complexity – Throttling based on capping concurrent threads is typically the simpler of the two solutions to implement. This will certainly be the case where the development platform provides built-in support for implementing managed thread pools, as per Java. However, rate limiting isn’t that tough to implement, and as noted above, there are libraries which even if not used directly provide example implementations. Therefore, complexity isn’t the main factor in the choice of approach. Complexity does however increase when you need a distributed rate limiting solution (see below).
2) Accuracy / Precision – When throttling by capping concurrent threads, the actual rate at which messages are consumed will vary depending on the performance of each worker node (how quickly each of the message consumer threads run). Rate limiting on the other hand allows you to precisely limit the rate at which messages are consumed, in terms of a configured throughput, regardless of the no. of active threads or performance of the server. Therefore when precision is required rate limiting is the only choice.
3) Flexibility – Throttling by capping the no. of active threads is a relatively blunt instrument, in so far as achieving the desired rate relies on pre-calculating the fixed units of work (e.g. no. of DB writes per message) which each execution of the task consumes. Rate limiting can provide more flexibility. The rate limiting API can allow client code (in this case message consumer tasks) to test whether rate is available before undertaking work; specify the no. of units of work they need to consume on each execution, which might vary; and also potentially block mid processing for a configured period of time until rate becomes available. This extra flexibility will result in a solution which is more efficient.
4) Distributed Support – Threads are locally managed resources. A solution based on top of a thread pool therefore only supports managing the rate of message consumption on individual servers. The same is true of the local rate limiting solution described above, based on a single RateLimiter class. If you have multiple, load-balanced instances of an application, to facilitate horizontal scaling, these solutions would require you to manage the rate limit in multiple places. Capping the total rate of all message consumers, deployed across all instances of the application, requires calculating the desired rate per worker node / server by dividing the overall required rate by the no. of instances of application. If you want to adjust (increase or decrease) the overall rate (e.g. on adding or removing an application instance), you have to re-calculate the split, and update it on each server. Whilst APIs (e.g. JMX) can be provided to support dynamically changing the rate on each server, it’s still essentially a manual task, which isn’t great for live / production operations.
If you do need to maintain an accurate total rate of consumption across multiple servers then distributed rate limiting can provide a solution. This can be built by modifying the local RateLimiter class to track and maintain the rate of message consumption across all servers by making a remote call to shared, centralised, in-memory cache. Redis would be a good choice for implementing such a cache, as it’s a proven solution that offers very high performance (low latency).
In summary, a distributed rate limiting solution also has a couple of advantages over a local rate limiting solution when there are multiple worker nodes for scalability –
- a) It’s possible to change (increase or decrease) the worker node capacity / pool size and still maintain a constant total rate of consumption, avoiding the need to have to adjust (increase or decrease) the rate on every worker node to compensate.
- b) If a change (increase or decrease) in the rate is required it now only needs to be applied in one place, rather than on every worker node.
Summary
Broadly speaking there are two approaches you can use to control the rate at which work is done by concurrent tasks in an application – capping max. concurrent threads and rate limiting.
Capping the concurrent threads will likely be slightly simpler to implement and can provide an acceptable solution where the requirement is primarily to have some control of the rate at which work is done. But if you require a higher level of accuracy / precision in attaining a target rate, or you need to manage the rate at which work is done across multiple, distributed servers, then rate limiting will likely be the better, or only workable solution.
For our use-case, we will adopt the simpler approach initially. Each worker node’s thread-pool will be configured with a max no. of active threads. For extra flexibility, a JMX API will be provided to allow this setting to be dynamically altered if needed. However, I suspect we will subsequently need to replace this with a distributed rate limiting solution in the future if we want to have greater control over the max load the worker node’s writes place on the DB server, and also to maintain a consistent rate when worker node capacity alters, e.g. during maintenance, upgrades or deployments.
Hope you found this useful.
