![]()
When building a message consumer you need to handle the various errors that will inevitably occur during message processing. If you’re using Amazon SQS as your message broker it provides some built-in support for error handling that you can utilise. But, if you want to handle all types of errors efficiently you should also add your own custom error handler. This post explains how you can do both these things, including how to classify message processing errors.
Understanding SQS’ Default Message Delivery Behaviour
If your message consumer encounters an error during the processing of an SQS message (at any point between receiving and acknowledging / deleting it), and it doesn’t have any error handling of its own, then the message will be left unacknowledged. SQS will make the message available again on the queue for re-processing after the Visibility Timeout expires. This sequence of events is show in the diagram below, taken from the SQS Developer Guide –
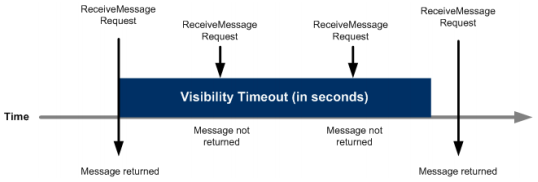
By default SQS will continue to republish an unacknowledged message until the message reaches a max age defined by the queue’s configured Message Retention Period. This is typically set to several days to ensure messages are retained when your message consumers are offline for an extended period during (planned or unplanned) outages. If your Visibility Timeout is set to the default of 30 seconds, and your Message Retention Period is set to the default of 4 days, then without taking any further measures your message consumers could end up unnecessarily attempting to reprocess the same ‘bad’ message over 10,000 times! This is a waste of money (SQS charges) and bandwidth, and the reason why most if not all SQS message consumer apps will need to apply additional error handling.
Use SQS’ Support for Dead Letter Queues
The good news is that SQS provides some built-in support for improving error handling that requires no additional development effort on your part.
SQS’ Redrive Policy feature allows you to instruct the SQS message broker to remove a message from a queue when your message consumer(s) have failed to receive (process) it a configured no. of times. The message is sent to a configured Dead Letter Queue (DLQ).
Enabling a Redrive Policy for your queue is a simple process.
First, create a second SQS queue to act as a DLQ for your source / inbound queue.
Then, configure a Redrive Policy for your source / inbound queue. As shown in the screen dump of the Amazon SQS admin console below, this entails configuring the name of the queue to use as the DLQ, and a parameter named Maximum Receives –
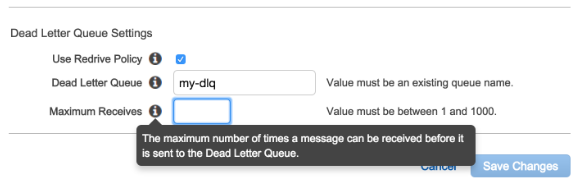
The main benefit of using a Redrive Policy is that it allows you to limit the no. of times your message consumer need to process a bad message, independently of the queue’s Message Retention Period, without any work on your part.
Distinguishing between Transient and Permanent Errors
Adding a Redrive Policy to your SQS queue is an improvement, but used alone it’s not ideal for all types of errors that can occur when consuming messages.
Broadly speaking there are two different categories of processing errors you’ll want to distinguish and handle differently.
Transient errors result in temporary failures to process a message. A common reason for this type of error is an unplanned outage of one of the services on which the message consumer relies e.g. its data-store. Other reasons include e.g. I/O errors, concurrent update errors, etc. Because these types of errors are temporary, processing of the message should be retried one or more times, until the error is resolved, because barring any other problems the message will still be processed successfully.
Permanent errors occur when the app’s message consumer is unable to process a given message, commonly referred to as a “bad apple”. This typically occurs when the message is invalid in some way, e.g. the payload doesn’t conform to an expected schema, mandatory fields within the payload are missing, or a failure of a business validation rule. However, they can also be caused by bugs in the message consumer that are only exposed by unusual or previously untested message state. When a permanent occurs there is no value in retrying the processing of the message, as it will always fail.
Handle Permanent Errors more Efficiently & Effectively
If your message consumer error handling relies solely on an SQS Redrive Policy, permanent errors will be handled in the same way as transient errors. This is inefficient as permanent errors will be unnecessarily retried for up to Maximum Receives, which incurs additional SQS (API and bandwidth) costs. This inefficiency can be addressed by implementing your own custom error handler for your message consumer which classifies an error during message processing as either permanent or transient and handles them differently.
In addition to lowering costs, there are other reasons why it’s worth implementing your own custom error handler for your message consumer. For example –
- You can take control of removing the bad message in your app. This allows you to include additional error diagnostics, which can be used to support offline investigation, and reporting on the cause of the bad message.
- You can log permanent errors differently, such as logging at a severity / priority level of “error” rather than “warning”, including the payload of the bad message, and the causal exception.
The pseudocode for the custom error handler looks something like this –
Error error = createError(exception)
if (error.isPermanent()) {
// Create an SQS message containing details of original message and error diagnostics,
// and send it to the dead-letter queue
String errorMsgId = createAndSendErrorMessage(message, error, dlqUrl)
// Remove bad message from system by acknowledging it - in SQS this entails deleting
// the message identified by its receipt handle
sqsClient.deleteMessage( createDeleteMessageRequest(inboundQueueUrl, receiptHandle) )
logPermanentError(message, error, errorMsgId)
} else {
logTransientError(message, error)
// Don’t acknowledge (delete) the original message - processing will instead timeout and
// it will be retried by SQS according to the queue’s configured Redrive Policy
}
After deploying this custom error handler, SQS will only handle transient errors. As a result an added benefit is that you can reconfigure the Redrive Policy with a higher Max Receives value, allowing you to ‘ride-out’ unplanned outages for longer, before rejecting messages.
Key Takeaways
When using Amazon SQS for your message broker –
1) Enable the use of a Redrive Policy on your SQS queue(s) to have Amazon automatically send messages to a dead-letter-queue of your choosing when the number of delivery attempts exceeds a queue-specific maximum, independently of the queue’s Max Retention Period.
2) Create and deploy a custom error handler for your message consumer to handle permanent errors differently to transient errors, and in a more efficient and effective way.
I hope you’ve found this post useful.
